
Enormt potentiale gemt i 200 år gamle data
Forskere på SDU har udviklet en teknologi, baseret på kunstig intelligens, der hurtigt kan transskribere og digitalisere gamle håndskrevne dokumenter som journaler, dødsattester og folketællinger. Det vil give adgang til en guldgrube af historisk viden.
Er der forskel på, hvilke sygdomme mennesker fik i forskellige egne af Danmark historisk set? Hvad var den hyppigste dødsårsag for 200 år siden? Og hvordan har den sociale mobilitet udviklet sig over tid?
Allerede i dag retter mange blikket mod Skandinaviens registre og arkiver, der gemmer på omfattende viden om borgerne, som i stort omfang benyttes til forskning.
Men skruer vi tiden tilbage til før 1980, er den slags data meget ofte ustrukturerede, håndskrevne og tager lang tid at gennemgå og sætte i system.
”Det tager måske 5-10 sekunder for en veltrænet maskine at læse og afkode et dokument som f.eks. en sygejournal, og det har vist sig, at den kan gøre det med rigtig stor præcision
Et hold forskere på SDU med professor Christian Møller Dahl i spidsen har nu givet sig i kast med at udvikle metoder, der automatisk kan gennemtrawle, aflæse og digitalisere, hvad der står skrevet i alt fra gamle journaler til folketællinger.
Data på tværs af generationer
- I Danmark har vi elektroniske registerdata, der går tilbage til 1980, men vi har faktisk 200 år gamle data på individniveau. Det er helt unikt, men en meget stor del af disse data er ikke digitaliseret og transskriberet.
- Ideen er, at hvis vi kan høste disse data og koble dem sammen med de eksisterende registerdata, så vil det være en enorm rig datakilde på tværs af generationer, siger Christian Møller Dahl og uddyber:
- Det arbejder vi på at gøre nu. Det tager måske 5-10 sekunder for en veltrænet maskine at læse et dokument som f.eks. en sygejournal, og det har vist sig, at den kan gøre det med rigtig stor præcision.
Om metoden
Forskerne kan trække på præcis de samme teknikker, som de anvender til at analysere finansielle data, dvs. maskinlæring og computer vision for at se mønstre i et billede. Og da Google og Facebook for et par år siden frigav de algoritmer, som de benytter til at identificere objekter – f.eks. hunde og katte – i billeder på internettet, viste det sig, at de to metoder kan kombineres, og et endnu ret uudforsket område så dagens lys.
Nogle af de dokumenter, forskerne har haft igennem maskinen, er fra 1950’erne. Børnedødeligheden herhjemme var stadig ret høj på det tidspunkt, og derfor begyndte man at sende sygeplejersker ud i de danske hjem for at følge de nyfødte børn efter fødslen og mindst et år frem.
Det fremgår f.eks. af dokumenterne, om barnets mor arbejdede, om barnet fik brystmælk eller ej, og hvor mange timer barnet sov.
- Der ligger en guldgrube af viden som denne, som vil kræve rigtig mange ressourcer at indtaste manuelt, for det drejer sig måske om 200.000 dokumenter eller flere. Målet er, at maskinen skal gøre hele arbejdet, siger Christian Møller Dahl.
Vil samle data 200 år tilbage
Han peger på, at man for at analysere visse ting skal meget længere tilbage end til 1980.
- Man kan f.eks. ikke analysere social mobilitet i et langt historisk perspektiv ud fra data, der kun er 30-40 år gamle. Dér skal du meget længere tilbage i tiden, siger han og tilføjer:
- Vi håber, at vi kan flytte den grænse til for 200 år siden, hvor man begyndte at have individobservationer, og at vi kan sammenholde de forskellige data. Det vil betyde, at vi kan sige noget om, hvordan sygdomme, social mobilitet, indkomst eller noget helt fjerde udvikler sig over tid. Det er ambitionen. Det er det store billede, vi gerne vil bidrage til.
Interessen er stor
Der har været stor interesse for forskningen fra mange sider. Forskerne er bl.a. i dialog med rigsarkivets afdelinger i bl.a. København og Odense, der ligger inde med folketællingerne, som er en vigtig kilde til information om vores forfædre.
Folketællingerne er blevet afholdt med jævne mellemrum siden 1769, og da registreringen indtil videre er foregået i hånden, er det meget tidskrævende at digitalisere disse data på manuel vis.
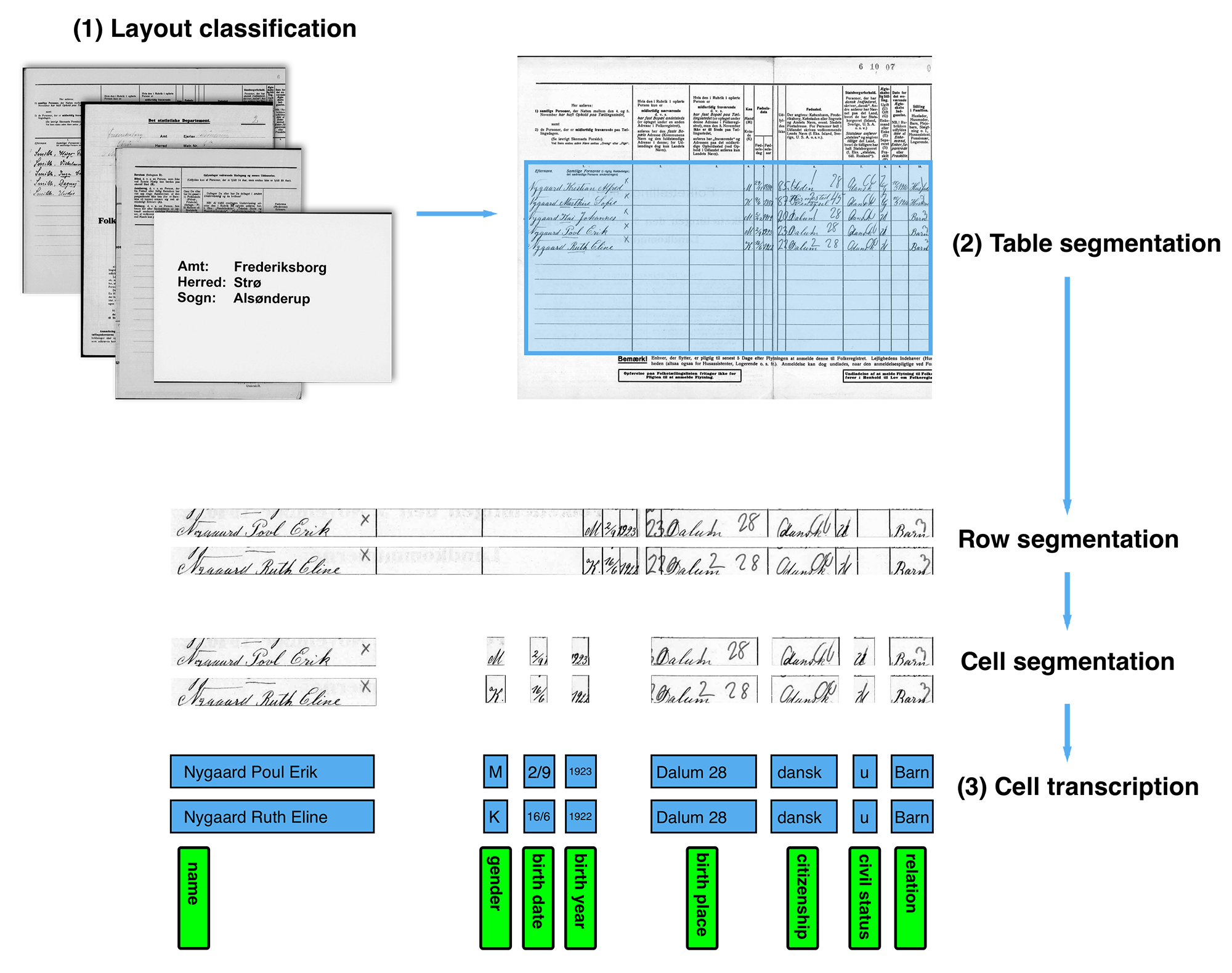
- Helt konkret gør vi det, at vi identificerer de dele af dokumenterne, vi er interesserede i at trække ud. Det kan være for- og efternavne, bopæl, alder og civilstatus. Derefter opdeler vi dokumentet i mindre felter og laver algoritmer for at lære maskinen, at den skal genkende netop de mønstre. Et dokument består af op til ti millioner pixels, og her kan maskinen stadig ikke være med, forklarer forskeren.
Arbejdsprocessen er gengivet i figuren nedenfor:
10.000 hjerner i kælderen
Han og kollegerne behøver ikke se sig meget omkring for at finde folk, der vil få stor glæde af de digitale data.
- I kælderen på SDU har vi en af verdens største samlinger af hjerner – næsten 10.000 hjerner fra psykiatriske patienter, som er indsamlet i perioden fra 1945 til 1982. Men journalerne er heller ikke blevet transskriberet, så det har vi tilbudt at hjælpe med, for at forskerne kan komme i gang med at undersøge hjernerne, fortæller Christian Møller Dahl.
Blandt samarbejdspartnerne er der også forskere på hans eget institut, der beskæftiger sig med økonomisk historie – et område hvor SDU står meget stærkt. Det samme gælder det interdisciplinære forskningscenter ”Center on Population Dynamics (CPOP)”, hvor forskerne er optaget af spørgsmål om aldring.
Forskningsgruppen
Ud over arbejdet med at udvikle algoritmer, der kan læse og omsætte håndskrevne data til elektronisk form, har forskningsgruppen også fokus på udvikling af redskaber, baseret på kunstig intelligens, til risikostyring og porteføljevalg indenfor finansiering, og gruppen løser bl.a. konsulentopgaver for finansielle virksomheder så forskellige steder som i Syddanmark og New York.
Derudover er gruppen i gang med et projekt for Arbejdstilsynet sammen med fakultetets analyseenhed. Projektet skal på baggrund af millioner af observationer hjælpe med at identificere og udpege de virksomheder, der er mest tilbøjelige til at bryde arbejdsmiljøregler. Ved brug af modellen vil Arbejdstilsynet både kunne gøre sit arbejde mere effektivt og skære markant ned på udgifterne til tilsyn af virksomheder.
Mød forskeren
Christian Møller Dahl er professor ved Institut for Virksomhedsledelse og Økonomi. I sin forskning beskæftiger han sig med forudsigelser baseret på big data, maskinlæring, computer vision, algoritmer og statistik. Han er desuden medlem af Danmarks Frie Forskningsfond – Samfund og erhverv.